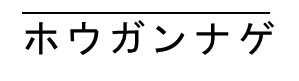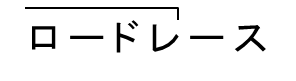ユーザー単語辞書¶
AITalk 製品の扱うユーザー単語辞書を説明します。 以降は「ユーザー単語辞書」は「単語辞書」と記します。
単語辞書はユーザー辞書の種類の 1 つです。 ユーザー辞書の概要については ユーザー辞書概要 を参照してください。
ユーザー単語辞書を用いると、AITalk 標準の言語辞書を拡張できます。 業界用語、人名、地名などの固有名詞や、新語など、標準の言語辞書に存在しない単語を補完したい場合に適しています。 単語辞書には、品詞・単語見出し・優先度・読み方・アクセント指定を登録する事ができます。
言語処理で選択される単語は、文の構成に依存するため、必ずしも登録した単語が選択され、その読み方になるとは限りません。
AITalk の言語処理を高速に行うため、テキスト形式の単語辞書ファイルからバイナリ形式の内部形式へ変換してから読み込む必要があります。
目次
単語辞書の使用例¶
例えば、以下の文を AITalk で読ませるとします。
紹介します、彼は神戸さんです。
「神戸」という苗字は、カンベ / カンド / ゴウド / コウベ、など様々な読みがあるため期待した通りの読みにならない場合があります。
ここでは、標準のまま読むと「カンベ」になるところ、「ゴウド」と読ませたかったとしましょう。 このような場合に、ユーザー単語辞書に意図した読みを登録することで、読みを修正することができます。 (文脈から AITalk が地名だと判断する場合は、標準では「コウベ」と読みます。)
以下がテキスト形式の単語辞書の例です。
1 2 3 | # <品詞>;<単語見出し>;<優先度>;<読み方>;<アクセント指定>
; ここはコメント行。「#」は先頭行。苗字「神戸」を「ゴウド」と読ませる。
名詞-固有名詞-人名-姓;神戸;1000;ゴウド;1-3:*
|
このユーザー単語辞書を読み込んでから再合成すると、ユーザー辞書の単語が優先されて「ゴウド」と読むようになります。
辞書フォーマット¶
テキスト形式の単語辞書は 1 つのテキストファイルです。 1 行ごとに単語を 1 つずつ指定できます。 以降、「単語辞書ファイル」については「wdic ファイル」と記載します。
具体的な wdic ファイルの記載例は次のようになります。
1 2 3 | # <品詞>;<単語見出し>;<優先度>;<読み方>;<アクセント指定>
; ここはコメント行。「#」は先頭行。
名詞-一般;りんごみかん;2000;アップルオレンジ;0-4,2-4:*
|
※ wdic ファイルの先頭行はヘッダー行になります。 以降、1 行ごとに 1 つのユーザー単語を記述します。
ファイル仕様¶
wdic ファイルはテキストファイルです。 以下の形式で記述します。
- 文字エンコーディング
UTF-8
- 改行文字
CRLF または LF
注釈
AITalk 4.1 以前のバージョンで使われていた wdic ファイルの文字エンコーディングは CP932 (Shift_JIS) でした。 最新の AITalk 5 では UTF-8 に仕様が変更されていることに注意してください。
4.1 以前の形式で作成された wdic ファイルは、ロードする前に文字エンコーディングを変換する必要があります。
先頭行 (ヘッダー行)¶
1 行目の行頭は必ず文字 # から開始しなければなりません。
この行はヘッダー行です。
ツールを用いて wdic を生成するときは、何らかの付加情報を記録することがあります。
コメント行¶
2 行目以降に登場する空行、または行頭が ; の行はコメントとして無視されます。
登録可能数¶
登録数に制限はありません。 登録数に比例してメモリ消費が増すため、メモリ不足にならないよう注意が必要です。
注釈
SDK 製品向け
同時に読み込める wdic ファイルは 32 ファイルまで です。
データエントリ¶
ヘッダー行以降の各行でユーザー単語を記述します。
ユーザー単語は文字 ; を区切り文字として、次の属性を指定します。
品詞
単語見出し
優先度
読み方
アクセント指定
データエントリ行の構成は次のようになっています。
<品詞>;<単語見出し>;<優先度>;<読み方>;<アクセント指定>
品詞¶
品詞には、以下のいずれかが指定できます。
名詞-一般
名詞-固有名詞-人名-一般
名詞-固有名詞-人名-姓
名詞-固有名詞-人名-名
名詞-固有名詞-地域-一般
名詞-固有名詞-一般
名詞-サ変接続
名詞-形容動詞語幹
記号-一般
単語見出し¶
単語見出しは、登録するユーザー単語の表層文字列を指定します。 以下の文字は利用できません。
。(全角 / 半角の両方とも)!(全角 / 半角の両方とも)?(全角 / 半角の両方とも)単語見出しの先頭、末尾にある空白文字
※ 単語見出しの文字数は最大で 30 文字までの制限があります。
日本語のアクセントについて¶
標準語のアクセント¶
日本語は単語の音の下がり目の位置によってアクセントが区別されます。 単語の中の下がる直前のモーラ (拍) をアクセント核と呼びます。
日本語の東京方言 (標準語) では、単語の中にアクセント核 (音の下がり目) は多くとも 1 つしか現れません。
また、1 モーラ目がアクセント核でない場合の音の上がり目は必ず 2 モーラ目になります。
そのため、そのアクセント核の位置 f と、アクセント句の長さ m によって単語のアクセントを指定できます。
見出し語 |
読み (アクセント付) |
アクセント型 |
アクセント指定 |
橋 |
|
0 型 |
0-2 |
箸 |
|
1 型 |
1-2 |
管理社会 |
|
4 型 |
4-6 |
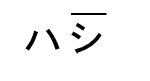

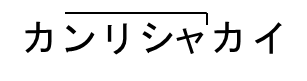
※ 横線「―」の部分は高く発音し、横線のない部分は低く発音します。
「  」で終わっている場合はその次の音が下がります。
」で終わっている場合はその次の音が下がります。
語によっては、複数のアクセント核を持つ場合があります。
見出し語 |
読み (アクセント付) |
アクセント型 |
アクセント指定 |
西郷隆盛 |
|
1 型、2 型 |
1-4,2-4 |
東京都中央区築地 |
|
3 型、3 型、0 型 |
3-5,3-5,0-3 |
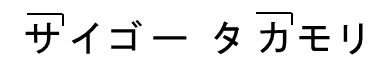
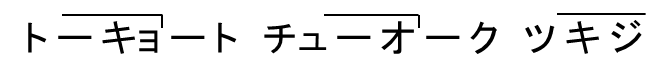
関西弁のアクセント¶
関西弁は標準語と違って音の上がり目は自明ではありません。 1 音目が低い場合 L 起式と呼び、1 音目が高い場合 H 起式と呼びます。
L 起式の場合、高い音は 1 音だけとなります。
そのため、アクセント指定は音の上がり目 r、アクセント核の位置 f、アクセント句の長さ m が必要になります。
見出し語 |
読み (アクセント付) |
アクセント指定 |
アクセント指定 |
砲丸投げ |
|
H 起式 |
1-0-6 |
ロードレース |
|
H 起式 |
1-4-6 |
三段跳び |
|
L 起式 |
6-0-6 |
バドミントン |
|
L 起式 |
3-3-6 |